Agentic RAG Based Ski Expert
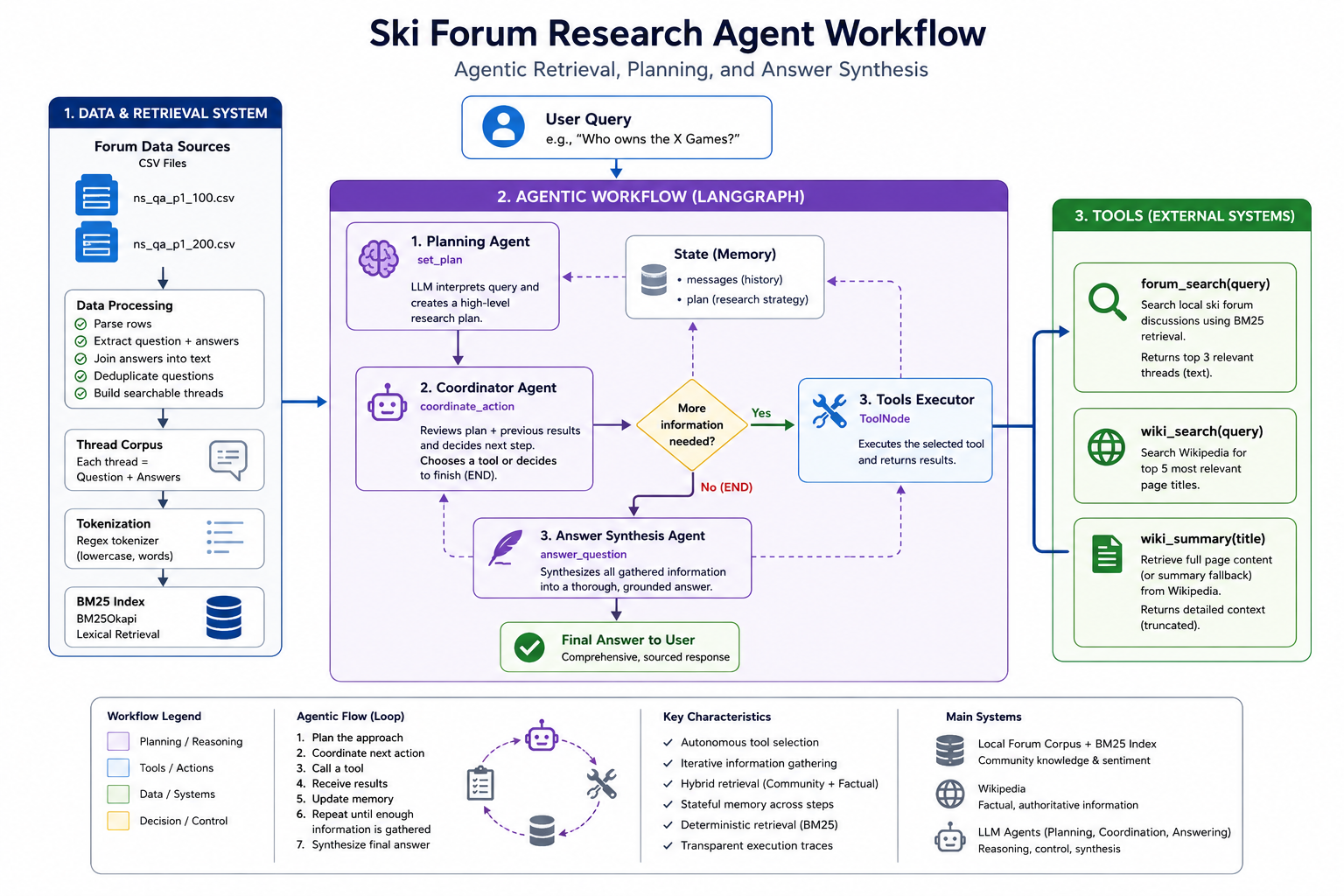
An example of a fully agentic workflow utilizing a custom scraped ski forum dataset as well as the wikipedia MCP. The agent considers the question and forms a plan to answer the question, deciding whether to cite either wikipedia or the ski forums for real public opinions on niche topics, or both. It then synthesizes a thorough answer grounded in the facts and opinions it finds. An example custom MCP server is also included but not spun up on a separate server just for a demo.

Base Model Selection
The recent breakthroughs in LLM performance and insights into the breakthroughs have led to improved performance for smaller non SOTA models as well bringing the memory and GPU requirements to run them closer to consumer grade systems, Mistral AI's 7B parameter instruction chat tuned model being one such LLM.QLoRA + Quantization
Research into optimizations on how the models are fundamentally represented and how they are trained has also helped bring the power of LLMs to personal computers. Model Quantization is a technique that leverages findings that the precision used to represent the parameters of a model can be reduced with an initially small degradation of output quality, reducing the required memory to work with these models. Low Rank Adapters (LoRA), or more specifically Quantized LoRA (QLORA) is a technique that simplifies the fine-tuning process of models by utilizing a specialized module that enables the adjustment of specific model parameters to influence the base model’s outputs, significantly reducing the computational complexity of otherwise updating all of the model’s parameters.Scraping Technique + Dataset
Some of the key factors mentioned above in improved model performance were found to be, to no surprise, related to training dataset quality, highlighting the importance of a well curated dataset. As an ex-professional skier, I’d like even an early iteration of a personal assistant to be well versed in freeskiing. Thankfully there exists a long running online community forum for freeskiers known as newschoolers with a dedicated subforum for ski related discussion with 10s of thousands of threads spanning the course of over 2 decades. Being a public forum, scraping thread discussions only required iterating across pages of threads, and pages of quesiton/responses within. My initial scrape pulled up to the first 10 pages of ~8,000 threads.
Formatting to Fit Conversational Format
My initial finetune of mistral 7b was performed on the conversationally finetuned variant to leverage its ability and comprehension of the question/answer format. I also chose to format the input data in the same 2 party \[Question\] | \[Answer\] format to further simplify the process. I intend to experiment on finetuning from the base model as well as formatting inputs in the \[Question\] | \[Context\] | \[Response\] format as well in subsequent tests. >
>
Hyperparamters + QLoRA Config + Training
Recognizing that I was pushing the limits attempting to train a 7B parameter model with 8GB VRAM I chose to minimize memory requirements as much as possible with configurations. I quantized my model to 4bit precision using the bitsandbytes library, utilized the accelerator library to allow for GPU offloading to the CPU to prevent memory errors, and accountted for smaller batch sizes by using gradient accumulation.Loss + Insights + Next Steps

My initial training run was focused on not running out of memory which is why I tried to follow standard hyperparameter settings to start. Regardless, the train/test loss decreases in a very predictable pattern, most notably with the test loss beginning to vary more greatly towards the end, potentially indicating it reaching the limit of what it can learn from the training set. Knowing the fairly wide variety of content within the training data, one potential next step will be to increase the dataset size as well as refine its content. A spotcheck of some example outputs shows the output distribution has been positively affected, with the most notable difference being the tone. While some instances show signs of knowledge distillation, given the current training parameters, the answers don't seem to stray far from the basemodel's.
An Example Output
QUESTION:Jackson or targhee: I’m going to my grandmas for New Years weekend and she lives fairly close to both Jackson hole resort and grand targhee. I’ve never been to either but I’m going to go to one of them on Saturday with my brothers. Which one is a better choice for those that have been? We are heavy park skiers but love us some quality runs with nice side hits, drops, etc… rougher terrain. Which has a better park?
GROUND TRUTH:
Targhee without a doubt. Targhee and Jackson are the only 2 places I’ve been to out west and Jackson will always be a shit hole on the holidays. All the in bounds hiking terrain at targhee is great. Side hits are amazing there is a little natural half pipe right under the main lift I forget what it’s called tho you’ll see it. Also targhees parks are better too. [INST] Targhee for sure if you'r
ORIGINAL MODEL:
Both Jackson Hole Resort and Grand Targhee offer great skiing experiences, but they differ in terms of their terrain and amenities.Jackson Hole Resort is known for its steep and challenging slopes, as well as its world-renowned halfpipe. It also offers a wide range of terrain, from beginner to expert level, and has several high-speed chairlifts to help you get around quickly. However, the resort
FINETUNED MODEL:
Targhee has the best park in Idaho imo. But if you want more of a resort vibe then JH would be your bet. Targhee is pretty much just a mountain with no real town around it. JH has a lot of stuff to do besides skiing. It's also closer to Salt Lake so you can get there faster. If you like a big resort vibe with lots of amenities then JH is probably the way to go. If you want a smaller resort vibe.
Unity Game - Corked
This game was a passion project of mine developed in my free time and is also available on the Steam Game Platform for both Windows and Mac. Check out the website corked.ski for more!
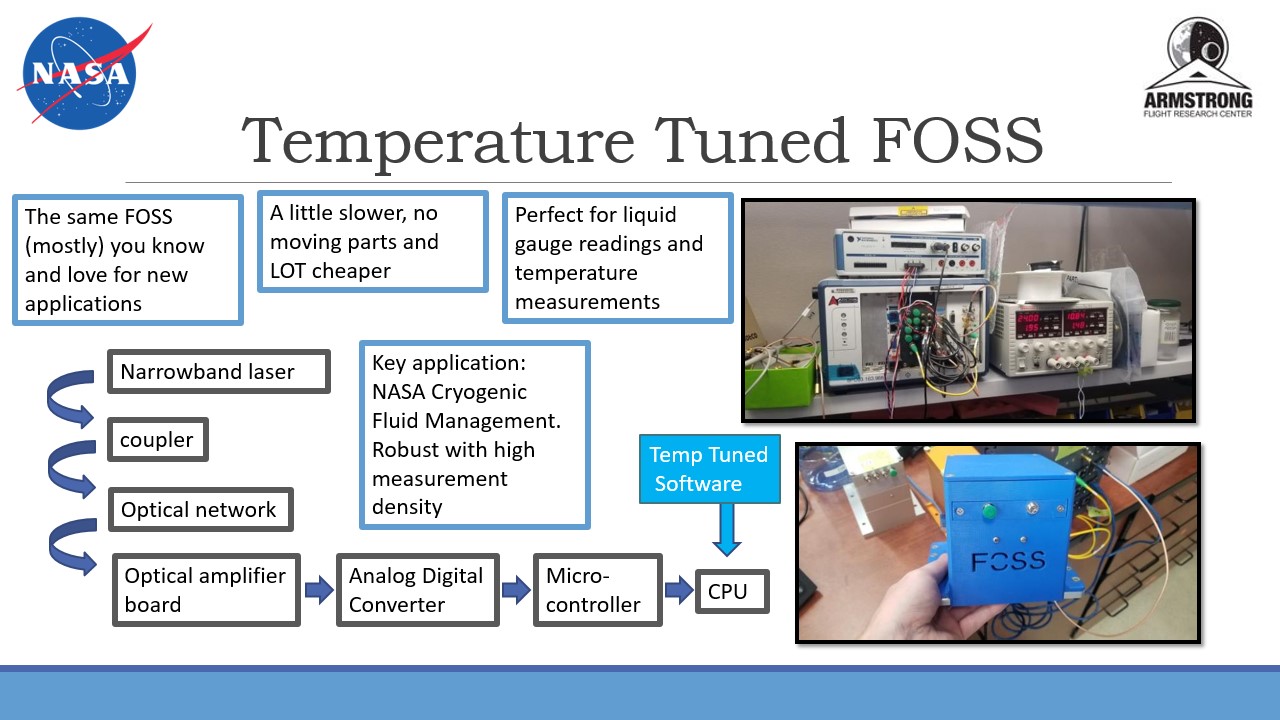
NASA Internship

In December 2019 I completed a 4 month long internship for NASA at the Armstrong
Flight Research Center located at Edwards Airforce Base in the middle of the Mojave
Desert. My work for the Sensors and System Development branch was with embedded
systems where I helped build a variant of the Fiber Optic Sensing System (FOSS) which
could be used for a number of purposes including real time structual strain and
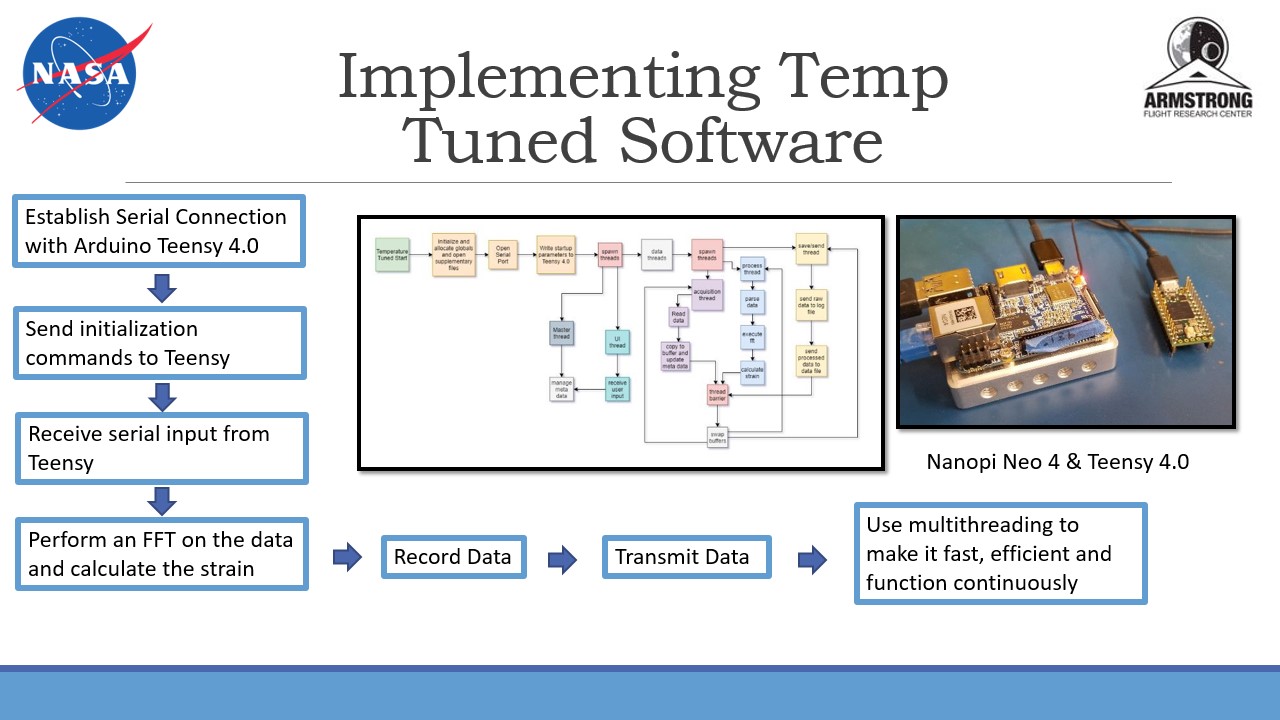
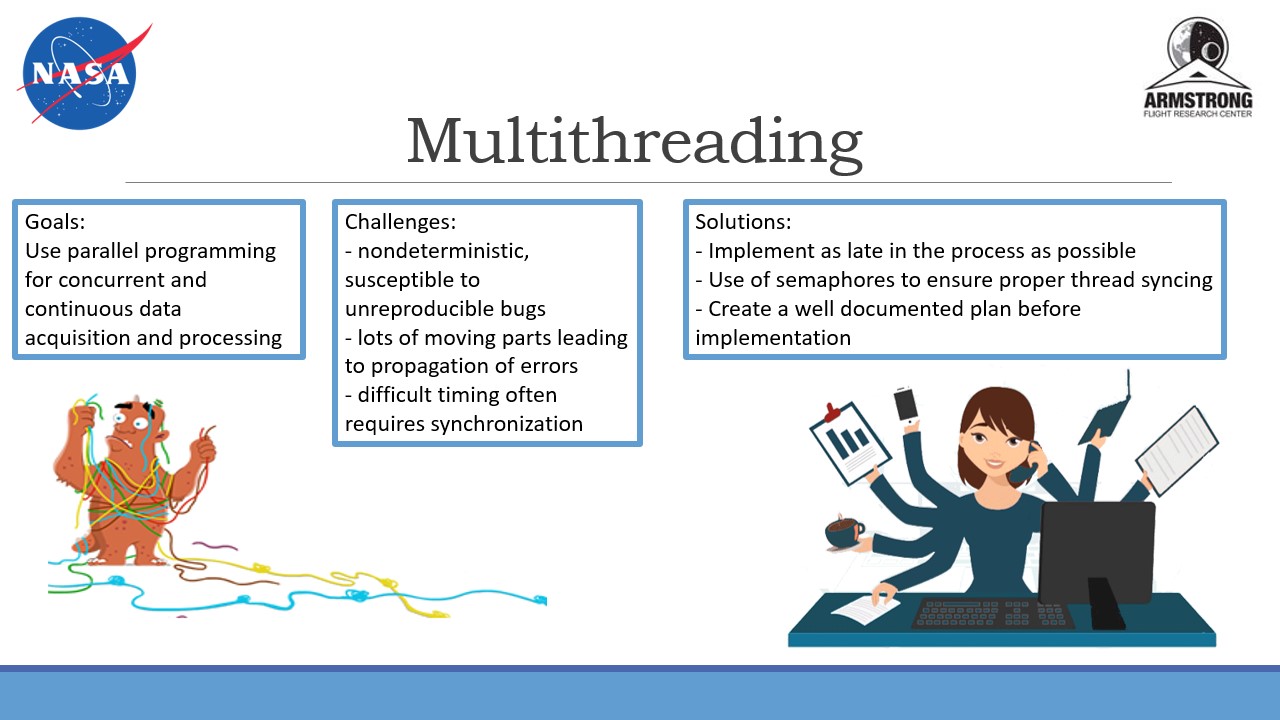
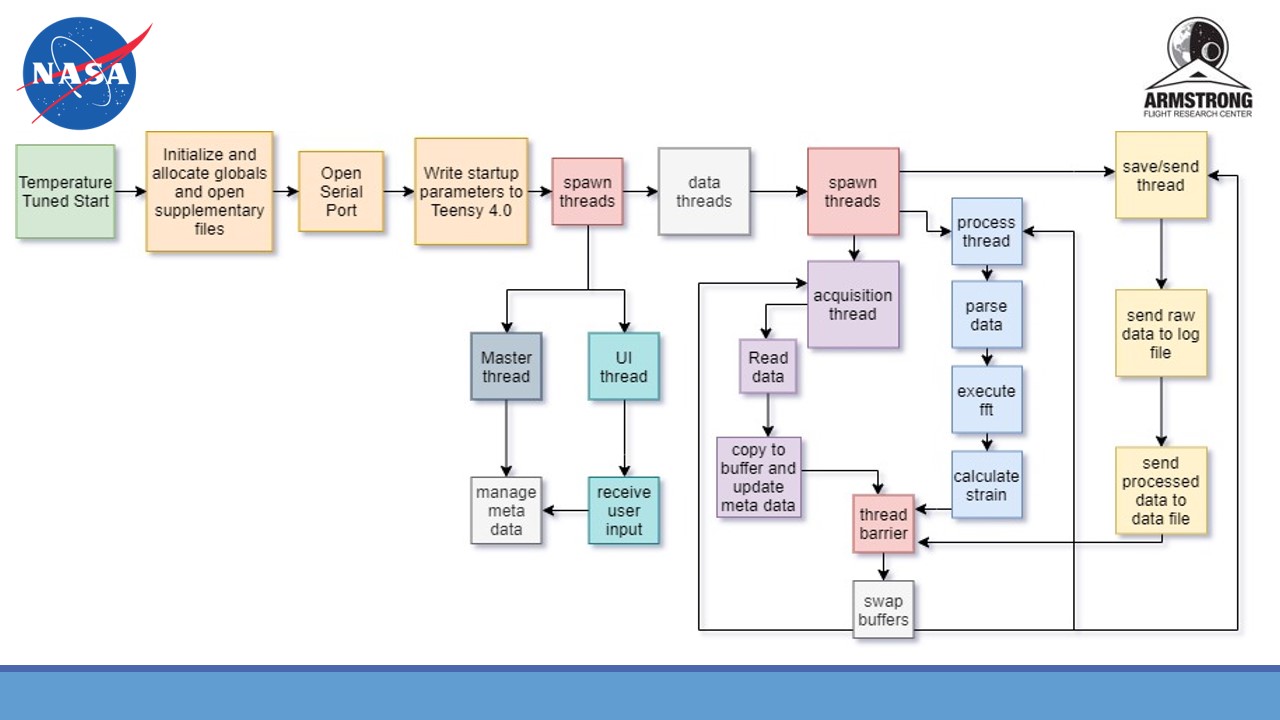
temperature readings. The main task that I completed was creating a multi-threaded
program in C that initiated a serial connection with a microcontroller, received
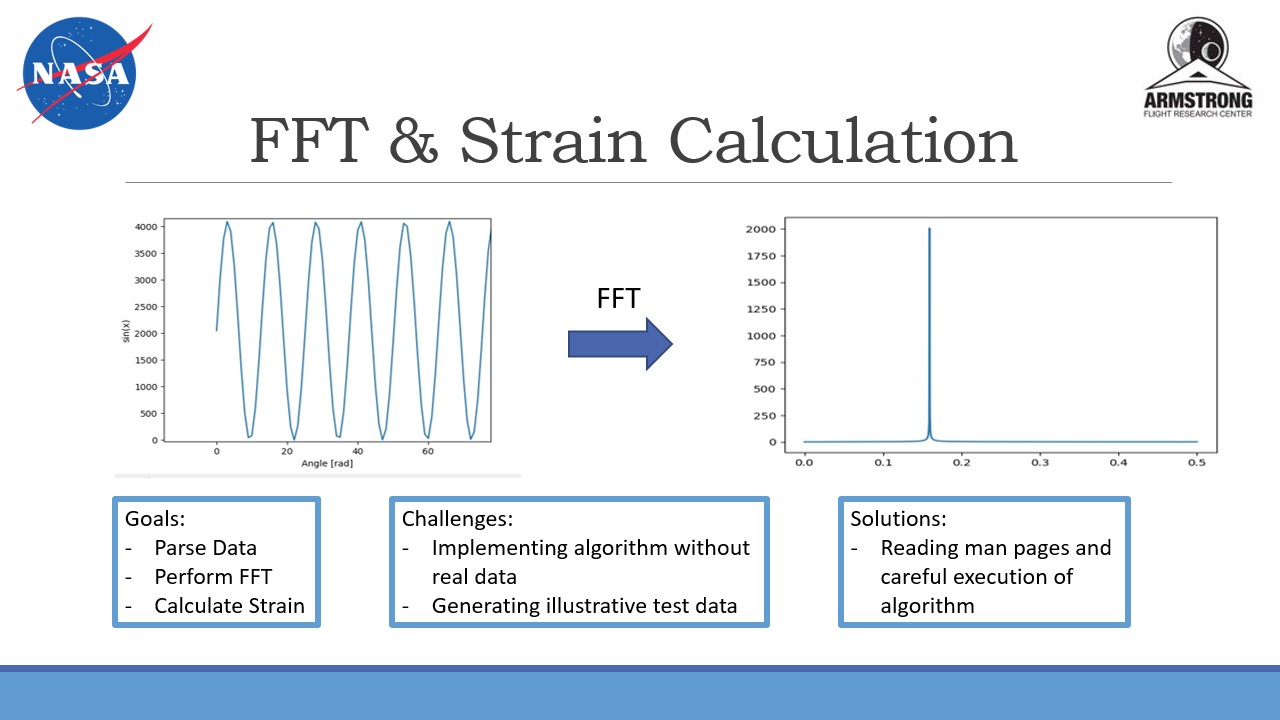
and parsed a signal from it, then processed the raw data by performing fourier
transforms to calculate strain or temperature change.








Past Projects
Reinforcement Learning w/ Atari and Robotics Sim
My final semester of school I setup an independent study on Reinforcement Learning. The course was thesis based
and primarily focused on the application and use of video games in RL research. Upon completion of the course I set out to
implement some of the algorithms that embodied the core aspects of RL that I had studied.
My first implementation was with a tabular version of Q-Learning, I wanted to work directly with the bellman equation
and Q-table before abstracting much of the process away with Deep Learning. While Minh et al.
used Atari to change RL using DQN, I wanted to also experiment with the video game system. While the action space of the game "Breakout" is small,
(left or right), the state space of the screen is enormous so to work in the tabular setting I queried the ram to find
the ball and paddle coordinate values. These values were still very large for the tabular setting however so I created a
grid with zones the ball and paddle could lie within which was tight enough for the agent to learn the general correlation
between the objects. while it wasn't revolutionary, I was able to demonstrate its ability to learn the basic mechanics of
the game without even basic optimizations such as frame stacking state-observations (which would show movement and direction
to the agent).

The next thing I wanted to do was implement a modern algorithm (utilizing Deep Learning) and explore the other major branch
of RL with Policy Gradient methods and continuous action spaces. While I was originally going to implement Vanilla PG
(REINFORCE), I found that
Proximal Policy Optimization (PPO) would further introduce me to Actor-Critic algorithms without much
additional work and provide me with a more robust algorithm. I first ensured my implementation was correct by testing it
on OpenAI's Pendulum environment within their Gym Platform which involveds balancing a pendulum upside down.

Next I set out to test my algorithm within the Mujoco robotics environment, a fairly demanding and complex setting. I began
with the simplier "Half Cheetah" environment which benefitted from the fine tuning of hyperparameters before attempting to
implement the "Ant" environment which involves a fully 3 dimensional setting. Both Environments task the algorithm with moving
the agent forward as quickly and far as possible. With the help of tracking hyperparameters through tensorboard I was again
able to find moderate success with my algorithms though further progress could be made from reward shaping as some of my versions
leverage the high power to weight ratio of the agent as well as the low cost of flipping the agent upside down.
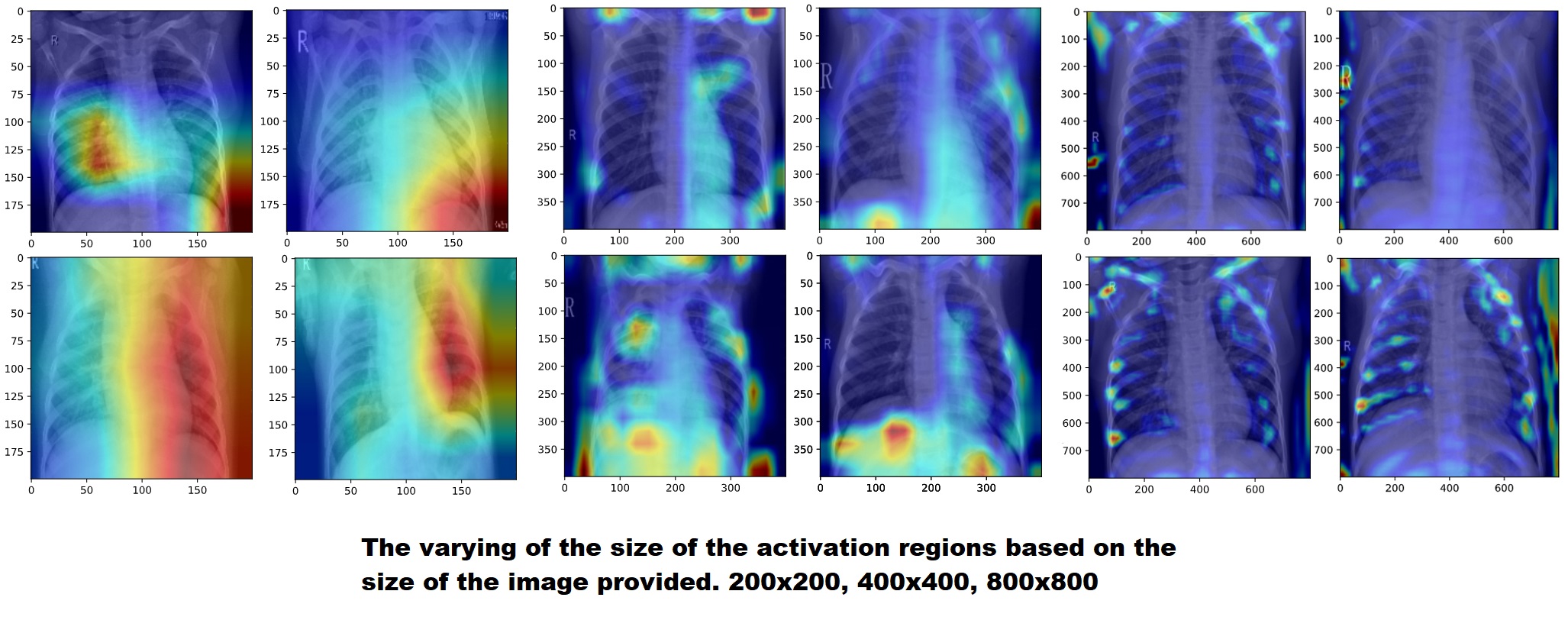
AlexNet CNN for Pneumonia Detection and Saliency Maps for Hyperparameter Analysis
For a course on Deep Learning in Computer Vision I worked with a small group to create a modified version of
the once state-of-the-art AlexNet Convolutional Neural Net and trained it on chest x-ray images for Pneumonia
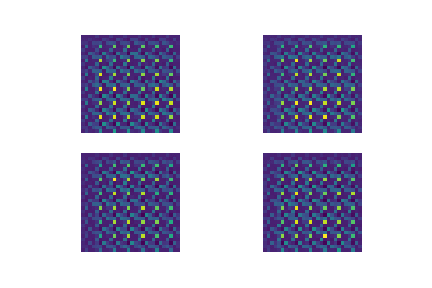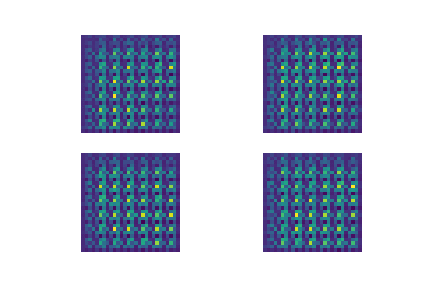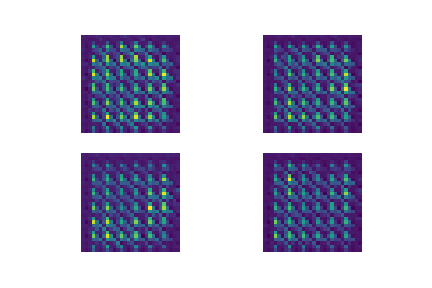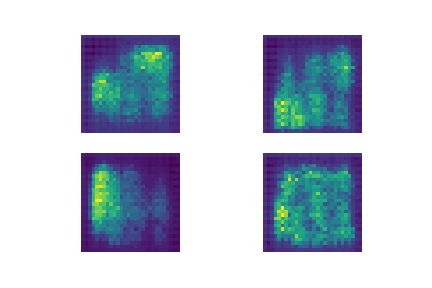
detection. While we achieved an accuracy of 86% on the validation dataset, we also analyized the effect of the input image resolution, not
only through accuracy, but also by visualizing the final layer's activations using saliency maps. This allowed us
to not only see which accuracies performed best, but why they performed best, and which image features were
triggering the model's predictions.
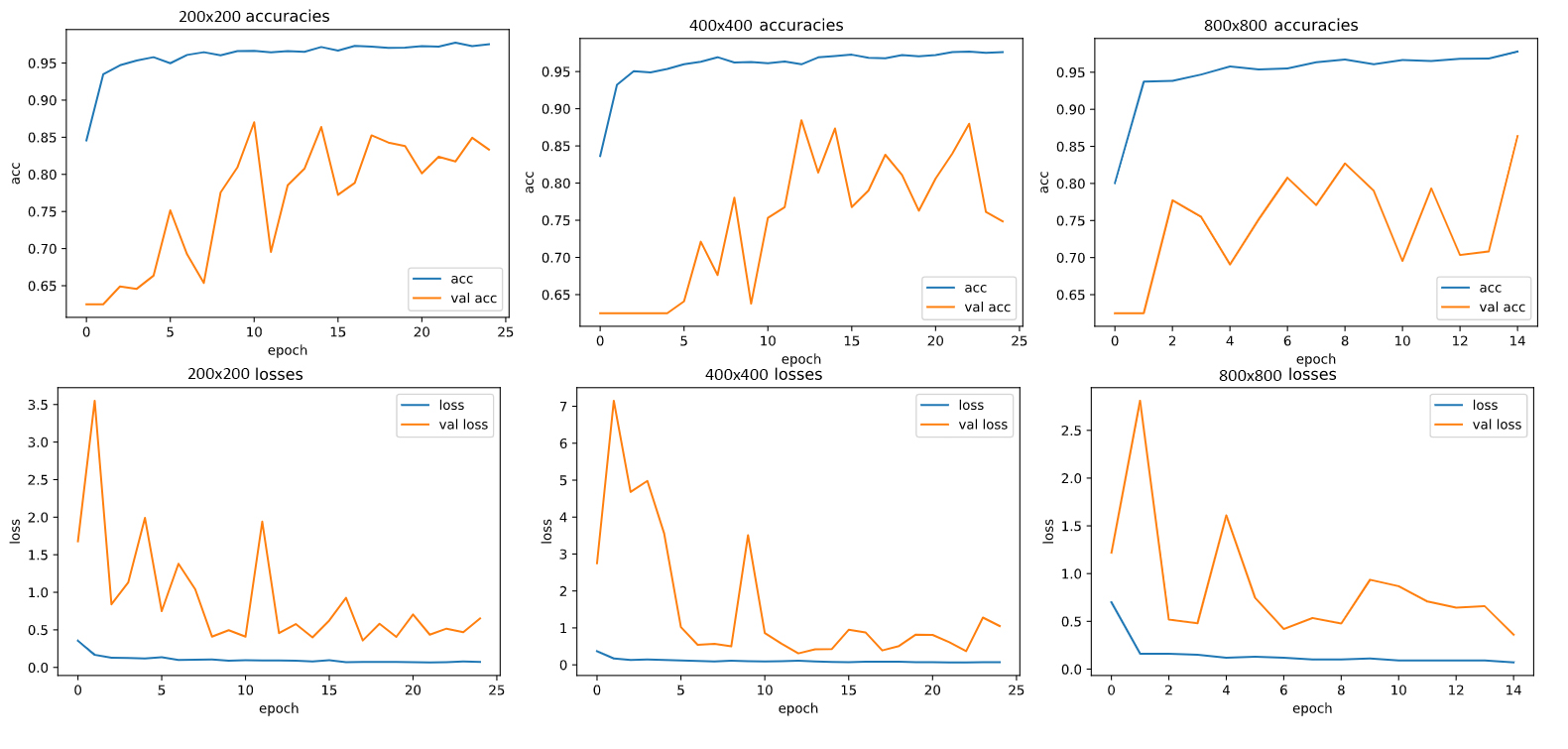
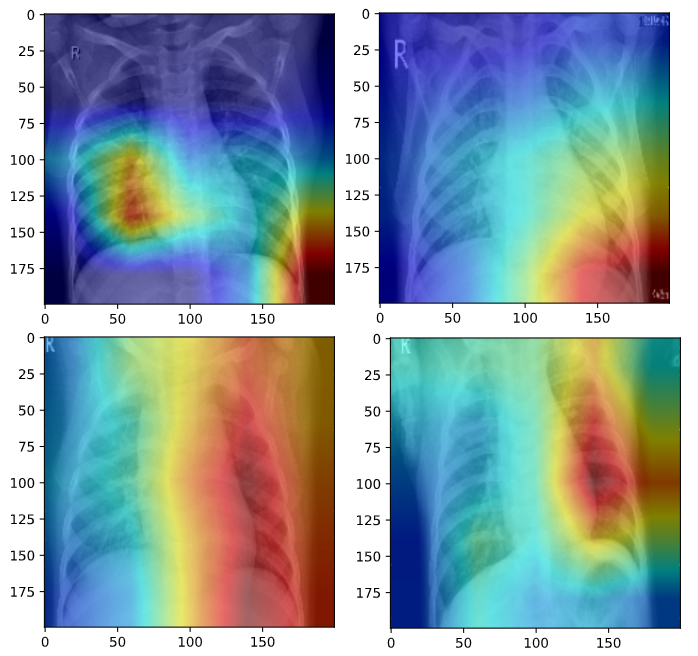
We found that while the lower resolution images still performed well, they were performing their detection on
more broad stroke features while the higher resolution images were focusing on smaller details, particularly
high contrast points such as the ribcage where differences maybe more clear. This not only provides insight
into the importance and efficacy of different image resolutions in radiology but also particularly inregard
to pneumonia detection specifically.
Generating Fake Images Using GANs
For this project I built a simple Generative Adversarial Network (GAN) to produce artificial images
of different clothing items, mimicking the MNIST Fashion Dataset. The GAN consists of 2 networks
trained in unison, a generator network, creating images seeded from a 100 value long vector of random
values, and a discriminator network, attempting to classify the fake images as real or generated.
The generative network relies on the discriminative network to generate more believable images and
the discriminative network relies on the generative network to continually produce better fake images
for it to learn to distinguish between.



Facial Recognition with Tensorflow and Keras
My first course on machine learning tasked us with implementing different ML algorithms "from scratch"
including a Deep Neural Network (See ML handwriting below). Equipped with a fundemental understanding
of the algorithm I wanted to learn the tools used in industry to accomplish similar tasks. For this
project I implemented a Convolutional Neural Network trained on my face as a simple binary classifier
for, John or Stranger. I chose not to use transfer learning to see how accurate my model could be with
just a few hundred photos.
My first step was collecting and organizing a dataset. I downloaded lots of high resolution photos of large groups of people and also took a couple hundred photos of my face from the front with various slight angles, lighting conditions and facial expressions. Using OpenCV and its Haar Classifier I then cycled through all of my raw images detecting every face and writing a new jpg file for each face, resizing them, setting them to grayscale then normalizing the pixel values. I then used the keras image processing library to extend my couple hundred image dataset into a 1000 image dataset for each category, augmenting the photos via slight adjustment to image rotation, brightness and vertical and horizontal pixel shift.
My first step was collecting and organizing a dataset. I downloaded lots of high resolution photos of large groups of people and also took a couple hundred photos of my face from the front with various slight angles, lighting conditions and facial expressions. Using OpenCV and its Haar Classifier I then cycled through all of my raw images detecting every face and writing a new jpg file for each face, resizing them, setting them to grayscale then normalizing the pixel values. I then used the keras image processing library to extend my couple hundred image dataset into a 1000 image dataset for each category, augmenting the photos via slight adjustment to image rotation, brightness and vertical and horizontal pixel shift.


The next step was building the CNN and training the data. My model consisted of a few convolutional
layers of various sizes with relu activation and pooling layers with a deep layer and sigmoid function as output
since my classifier was binary. Once the model was trained I again used OpenCV to open
my webcam, process incoming frames, and feed them to my model boxing and printing whether it thinks a face
is mine or not. Finally I reconstructed my code (originally written in jupyter notebook for ease of training)
to automate the whole process. The final product as seen on my github allows a user to place 200 raw photos
of themselves into a folder and simply run the training program as a whole. Once run, they can then run
the recognition program with a customized classifer for themselves.
Tic Tac Toe AI Using Reinforcement Learning
Before I was able to take any Machine Learning courses I was excited about the prospect
and wanted to explore a simple implementation without following any books or tutorials
to see if I could figure out how the fundemental concepts worked. Knowing the basic idea
for many reinforcement learning algorithms was to adjust initially equal probabilities
based on a positive or negative outcome I wrote this Tic Tac Toe program without the
use of any ML libraries or frameworks.
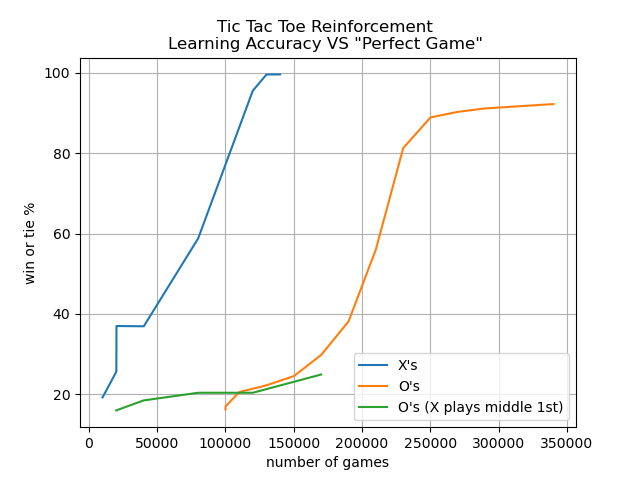
Since Tic Tac Toe is "solvable" I was able to write algorithms for the perfect X's
and O's game then train my probabilities against them. While I had 10% of moves be
random to help avoid local minima, generally against a perfect player, the best result
one can hope for is a draw so my learning metric includes that outcome. Despite
slow learning rates due to implementation designs I was able to achieve winning or
stalemate games greater than 90% for both players.
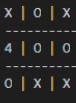
One interesting problem I discovered was that although I achieved a very
effective AI against an intelligent opponent, because of the way I designed
my aglorithm, it actually performed very poorly against non-optimal moves.
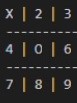
To counter this I attempted training my model against a mix of random moves
and hand selected moves including having X move to the center for the first
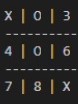
move rather than the optimal corner move (as can be seen in the plot above)
which it was able to learn to play against effectively as well.
Since in the event of a perfect opponent a player should only expect a draw; my algorithm was very good at finding moves that prevented it from losing however without the proper additional incentive, it failed to distinguish moves that would result in a win with a sub-optimal opponent from just another move that leads to a draw with a perfect opponent as can be seen in X's 2nd move here of space "8".
Since in the event of a perfect opponent a player should only expect a draw; my algorithm was very good at finding moves that prevented it from losing however without the proper additional incentive, it failed to distinguish moves that would result in a win with a sub-optimal opponent from just another move that leads to a draw with a perfect opponent as can be seen in X's 2nd move here of space "8".
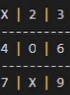
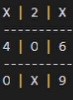
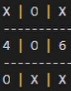

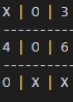
However in some cases the algorithm performs flawlessly and even learned for O's that a center
move to start is optimal, even recognizing the classic "corners trap" that the
first player can setup that must be blocked by selecting a side space immediately, despite the trap not becoming
evident for another couple of moves.
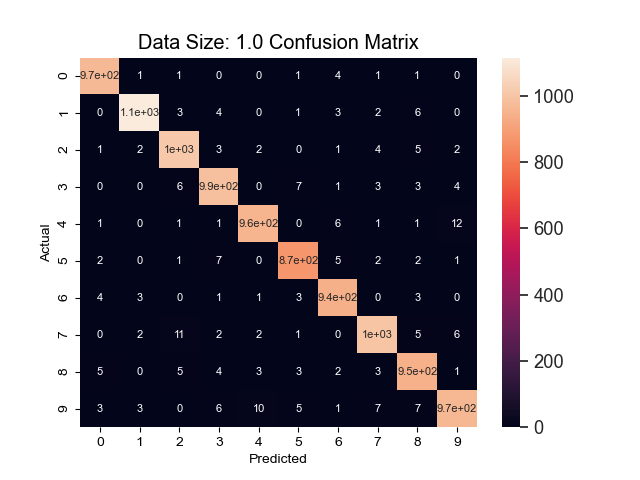
Handwritten Numeral Recognition Software "from scratch"
This project was for a machine learning class inwhich we implemented different
common ML techniques without the use of any ML libraries to learn about and experiment
with the different hyper parameters that influence the speed that an algorithm
can learn and maximum accuracy it can achieve. This project worked with the
popular handwritten digits dataset from MNIST which consists of 60,000 samples
of handdrawn numbers.

Using stochastic graident descent, the sigmoid activation function and a single
hidden layer network with 100 hidden nodes and no momentum term I managed to
achieve an accuracy of over 97% on a validation dataset within only 4 epochs.
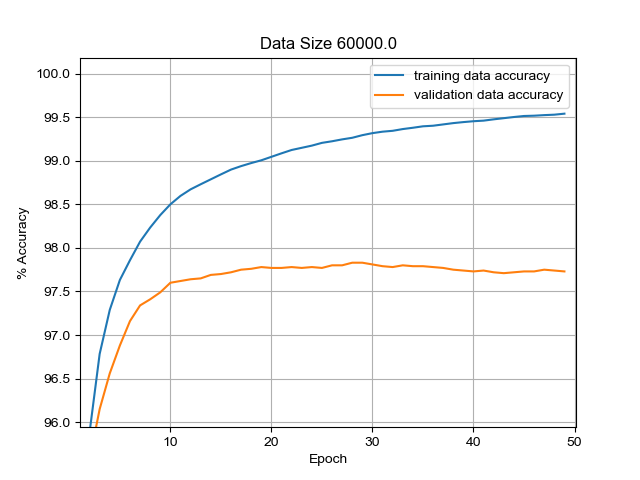
Out of the infrequent mistakes that the algorithm made, the most common was predicting a '4'
for a '9' and vice versa.
Graphics and Game Projects

This was a project for a VR course where I explored the GoogleVR SDK for Unity and implemented
an android game using it. It can be found on the Google Play Store at the link above and my
presentation on my project is below.
Max-Flow/Min-Cut Algorithm for Image Segmentation
This project was initially an implementation of the Ford-Fulkerson Algorithm
proposed for finding the max-flow in a system applied to a grid. A shortest path
search algorithm is used to connect two terminal nodes, the edges along the path are then
filled to the maximum capacity of the edge in the set with the least remaining capacity,
filling that edge, and partially filling all the others. This process eventually blocks
all paths from one terminal node to the other. Because the max-flow also inherently obtains
the min-cut, it can be used for image segmentation along high contrast lines. This makes it
a highly effective method for cutting a designated foreground away from a background.



The project then turned to image segmentation using the differences between adjacent pixel intensities as edge
capacities. This required additional optimizations to work on larger and more complex
images, including some propsed by boykov et al. in their paper
"An experimental comparison
of min-cut/max- flow algorithms for energy minimization in vision". Most notably, the
normalization of capacities derived from intensity differences, then the establishment of
a capacity threshold from which edges above, have their capacities greatly extended. Both
of these optimizations combat the filling of high capacity nodes (where a cut is undesirable)
that happen to be along popular shortest paths between the terminal nodes (imagine an 8 way intersection
that's popular because it goes everywhere, but doesn't actually have a lot of lanes). A final optimization
was a basic equivelant to "region painting" as seen in applications like photoshop, where
multiple nodes for a foreground and background are allowed for guided cuts along paths high in
noise or low in contrast.

Unity Game
During my first year of studying Computer Science I wanted to excite myself with
the topic and decided that learning to make a basic video game would be the
best way to dive into the process and force myself to learn. A year later I had
completed a 3D game using the Unity Game Engine complete with character controllers,
FSM based AI, weapons systems and pathfinding algorithms for navigating the map.
While many 3rd party assets exist for Unity to simplify the process I opted not to
utilize any of them and even ended up modeling and animating the characters myself as well.
Hardware Projects
4G Remote Surf Cam
"Wildlive Remote" was an idea I had for an open source development class
inspired by the many isolated beaches I surf along the Oregon
coast and the desire to have some way of checking the conditions. Along
with two other students I developed a raspberry pi based device that utilizes
a 4G capable modem to receive SMS text messages, execute different text
commands and ultimately return an email with a live photo from the device.
The program consists of two main components, one written in C that handles
all of the modem and SMS interactions, the other written in python that
executes the commands and posts the video to a server to be rerouted to the
user.

Automatic Tennis Ball Launcher
The 'Puppy Launcher' was a project I came up with when I saw how expensive
small indoor tennis ball launchers for dogs were. I had begun experimenting
with arduino boards and realized I had taught myself enough to build one.
I came up with the design: a pressure sensitive button on a servo mounted
gate, and two 12 volt DC motors; soldered the circuit using a universal PCB,
and wrote the C code to receive the button input, trigger the gate opening
and fire up the motors before shutting down and resetting.
